Part-2 of the invoice generation series in Elixir, Go vs Rust, When invoices settlement goes wrong
So lets build the invoice settlement system and see if todays’ tech stack will be able to solve the 10 years old problems we faced.
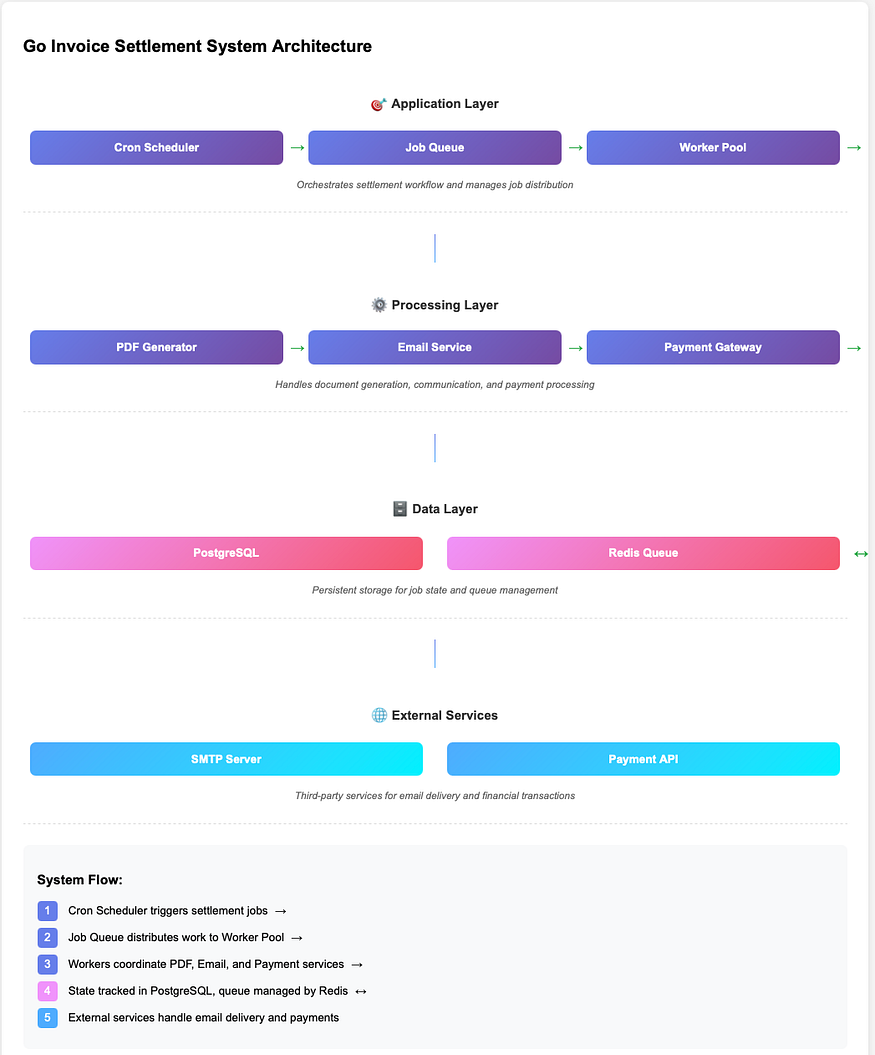
The Challenges We Must Solve
1. State Management
- Track which invoices are being processed
- Handle partial failures (PDF generated but email failed)
- Resume from last known state after crashes
2. Error Handling
- Network timeouts
- PDF generation failures
- Database connection issues
- External service unavailability
3. Concurrency
- Process multiple invoices simultaneously
- Avoid race conditions
- Handle worker crashes gracefully
4. Observability
- Monitor job progress
- Alert on failures
- Audit trail for compliance
Go Implementation: The Manual Way
1. DB Schema
-- jobs table for state management
CREATE TABLE invoice_jobs (
id SERIAL PRIMARY KEY,
vendor_id INTEGER NOT NULL,
settlement_period VARCHAR(20) NOT NULL,
status VARCHAR(20) DEFAULT 'pending',
started_at TIMESTAMP,
completed_at TIMESTAMP,
error_message TEXT,
retry_count INTEGER DEFAULT 0,
created_at TIMESTAMP DEFAULT NOW()
);
-- job steps for granular tracking
CREATE TABLE job_steps (
id SERIAL PRIMARY KEY,
job_id INTEGER REFERENCES invoice_jobs(id),
step_name VARCHAR(50) NOT NULL,
status VARCHAR(20) DEFAULT 'pending',
started_at TIMESTAMP,
completed_at TIMESTAMP,
error_message TEXT,
step_data JSONB
);Code language: SQL (Structured Query Language) (sql)2. Core Job Structure
package main
import (
"context"
"database/sql"
"encoding/json"
"fmt"
"log"
"time"
"github.com/go-redis/redis/v8"
_ "github.com/lib/pq"
)
// Job represents an invoice settlement job
type Job struct {
ID int `json:"id"`
VendorID int `json:"vendor_id"`
SettlementPeriod string `json:"settlement_period"`
Status string `json:"status"`
StartedAt *time.Time `json:"started_at"`
CompletedAt *time.Time `json:"completed_at"`
ErrorMessage string `json:"error_message"`
RetryCount int `json:"retry_count"`
CreatedAt time.Time `json:"created_at"`
}
// JobStep tracks individual steps within a job
type JobStep struct {
ID int `json:"id"`
JobID int `json:"job_id"`
StepName string `json:"step_name"`
Status string `json:"status"`
StartedAt *time.Time `json:"started_at"`
CompletedAt *time.Time `json:"completed_at"`
ErrorMessage string `json:"error_message"`
StepData map[string]interface{} `json:"step_data"`
}
// InvoiceProcessor handles the complex invoice settlement logic
type InvoiceProcessor struct {
db *sql.DB
redis *redis.Client
pdfService *PDFService
emailService *EmailService
paymentService *PaymentService
}Code language: Go (go)3. State Management — The Heavy Lifting
// ProcessInvoice handles the entire invoice settlement workflow
func (ip *InvoiceProcessor) ProcessInvoice(ctx context.Context, job *Job) error {
// Update job status to running
if err := ip.updateJobStatus(job.ID, "running"); err != nil {
return fmt.Errorf("failed to update job status: %w", err)
}
// Step 1: Generate Invoice Data
step1 := &JobStep{
JobID: job.ID,
StepName: "generate_invoice_data",
Status: "running",
}
if err := ip.createJobStep(step1); err != nil {
return fmt.Errorf("failed to create step: %w", err)
}
invoiceData, err := ip.generateInvoiceData(ctx, job.VendorID, job.SettlementPeriod)
if err != nil {
ip.updateStepStatus(step1.ID, "failed", err.Error())
return fmt.Errorf("invoice data generation failed: %w", err)
}
step1.StepData = map[string]interface{}{
"invoice_amount": invoiceData.TotalAmount,
"line_items_count": len(invoiceData.LineItems),
}
ip.updateStepStatus(step1.ID, "completed", "")
// Step 2: Generate PDF - Critical point where failures often happen
step2 := &JobStep{
JobID: job.ID,
StepName: "generate_pdf",
Status: "running",
}
if err := ip.createJobStep(step2); err != nil {
return fmt.Errorf("failed to create step: %w", err)
}
pdfPath, err := ip.pdfService.GeneratePDF(ctx, invoiceData)
if err != nil {
ip.updateStepStatus(step2.ID, "failed", err.Error())
return fmt.Errorf("PDF generation failed: %w", err)
}
step2.StepData = map[string]interface{}{
"pdf_path": pdfPath,
"file_size": ip.getFileSize(pdfPath),
}
ip.updateStepStatus(step2.ID, "completed", "")
// Step 3: Send Email
step3 := &JobStep{
JobID: job.ID,
StepName: "send_email",
Status: "running",
}
if err := ip.createJobStep(step3); err != nil {
return fmt.Errorf("failed to create step: %w", err)
}
emailID, err := ip.emailService.SendInvoiceEmail(ctx, job.VendorID, pdfPath)
if err != nil {
ip.updateStepStatus(step3.ID, "failed", err.Error())
return fmt.Errorf("email sending failed: %w", err
return fmt.Errorf("email sending failed: %w", err)
}
step3.StepData = map[string]interface{}{
"email_id": emailID,
"sent_at": time.Now(),
}
ip.updateStepStatus(step3.ID, "completed", "")
// Step 4: Initiate Payment
step4 := &JobStep{
JobID: job.ID,
StepName: "initiate_payment",
Status: "running",
}
if err := ip.createJobStep(step4); err != nil {
return fmt.Errorf("failed to create step: %w", err)
}
paymentID, err := ip.paymentService.InitiatePayment(ctx, invoiceData)
if err != nil {
ip.updateStepStatus(step4.ID, "failed", err.Error())
return fmt.Errorf("payment initiation failed: %w", err)
}
step4.StepData = map[string]interface{}{
"payment_id": paymentID,
"amount": invoiceData.TotalAmount,
"status": "pending_approval",
}
ip.updateStepStatus(step4.ID, "completed", "")
// Mark job as completed
if err := ip.updateJobStatus(job.ID, "completed"); err != nil {
return fmt.Errorf("failed to update job status to completed: %w", err)
}
return nil
}Code language: Go (go)4. Retry Logic and Error Handling
// RetryableProcessor wraps our processor with retry logic
type RetryableProcessor struct {
processor *InvoiceProcessor
maxRetries int
retryDelay time.Duration
}
func (rp *RetryableProcessor) ProcessWithRetry(ctx context.Context, job *Job) error {
var lastErr error
for attempt := 0; attempt <= rp.maxRetries; attempt++ {
if attempt > 0 {
// Exponential backoff
delay := time.Duration(attempt) * rp.retryDelay
log.Printf("Retrying job %d (attempt %d) after %v", job.ID, attempt, delay)
select {
case <-time.After(delay):
case <-ctx.Done():
return ctx.Err()
}
}
// Check if we can resume from a previous step
lastCompletedStep, err := rp.processor.getLastCompletedStep(job.ID)
if err != nil {
return fmt.Errorf("failed to get last completed step: %w", err)
}
// Resume from where we left off
err = rp.resumeFromStep(ctx, job, lastCompletedStep)
if err == nil {
return nil // Success!
}
lastErr = err
// Update retry count
job.RetryCount++
rp.processor.updateJobRetryCount(job.ID, job.RetryCount)
log.Printf("Job %d failed (attempt %d): %v", job.ID, attempt+1, err)
}
// All retries exhausted
rp.processor.updateJobStatus(job.ID, "failed")
return fmt.Errorf("job failed after %d attempts: %w", rp.maxRetries+1, lastErr)
}
// resumeFromStep allows us to restart from specific steps
func (rp *RetryableProcessor) resumeFromStep(ctx context.Context, job *Job, lastStep string) error {
switch lastStep {
case "":
// Start from beginning
return rp.processor.ProcessInvoice(ctx, job)
case "generate_invoice_data":
// Skip invoice data generation, start from PDF
return rp.processor.ProcessFromPDFGeneration(ctx, job)
case "generate_pdf":
// Skip to email sending
return rp.processor.ProcessFromEmailSending(ctx, job)
case "send_email":
// Skip to payment initiation
return rp.processor.ProcessFromPaymentInitiation(ctx, job)
default:
return fmt.Errorf("unknown step: %s", lastStep)
}
}Code language: Go (go)5. Worker Pool for Concurrency
// WorkerPool manages concurrent processing
type WorkerPool struct {
processor *RetryableProcessor
workerCount int
jobQueue chan *Job
quit chan bool
wg sync.WaitGroup
}
func NewWorkerPool(processor *RetryableProcessor, workerCount int) *WorkerPool {
return &WorkerPool{
processor: processor,
workerCount: workerCount,
jobQueue: make(chan *Job, 100), // Buffered channel
quit: make(chan bool),
}
}
func (wp *WorkerPool) Start(ctx context.Context) {
for i := 0; i < wp.workerCount; i++ {
wp.wg.Add(1)
go wp.worker(ctx, i)
}
log.Printf("Started %d workers", wp.workerCount)
}
func (wp *WorkerPool) worker(ctx context.Context, workerID int) {
defer wp.wg.Done()
for {
select {
case job := <-wp.jobQueue:
log.Printf("Worker %d processing job %d", workerID, job.ID)
if err := wp.processor.ProcessWithRetry(ctx, job); err != nil {
log.Printf("Worker %d failed to process job %d: %v", workerID, job.ID, err)
// Send to dead letter queue or alert system
wp.handleFailedJob(job, err)
} else {
log.Printf("Worker %d completed job %d", workerID, job.ID)
}
case <-wp.quit:
log.Printf("Worker %d shutting down", workerID)
return
case <-ctx.Done():
log.Printf("Worker %d cancelled", workerID)
return
}
}
}
func (wp *WorkerPool) SubmitJob(job *Job) {
select {
case wp.jobQueue <- job:
// Job queued successfully
default:
// Queue is full, handle overflow
log.Printf("Job queue full, job %d will be retried later", job.ID)
// Could save to database for later retry
}
}
func (wp *WorkerPool) Stop() {
close(wp.quit)
wp.wg.Wait()
}
func (wp *WorkerPool) handleFailedJob(job *Job, err error) {
// Send to dead letter queue for manual investigation
deadLetterJob := map[string]interface{}{
"job_id": job.ID,
"vendor_id": job.VendorID,
"error": err.Error(),
"failed_at": time.Now(),
}
// In a real system, you might:
// 1. Send to a dead letter queue
// 2. Alert the operations team
// 3. Create a support ticket
// 4. Log to monitoring system
log.Printf("Job %d sent to dead letter queue: %v", job.ID, deadLetterJob)
}Code language: Go (go)6. Health Monitoring and Recovery
// HealthMonitor tracks system health and handles recovery
type HealthMonitor struct {
db *sql.DB
redis *redis.Client
workerPool *WorkerPool
checkInterval time.Duration
}
func (hm *HealthMonitor) Start(ctx context.Context) {
ticker := time.NewTicker(hm.checkInterval)
defer ticker.Stop()
for {
select {
case <-ticker.C:
hm.performHealthChecks(ctx)
hm.recoverStuckJobs(ctx)
case <-ctx.Done():
return
}
}
}
func (hm *HealthMonitor) performHealthChecks(ctx context.Context) {
// Check database connectivity
if err := hm.db.PingContext(ctx); err != nil {
log.Printf("Database health check failed: %v", err)
// Alert operations team
}
// Check Redis connectivity
if err := hm.redis.Ping(ctx).Err(); err != nil {
log.Printf("Redis health check failed: %v", err)
// Alert operations team
}
// Check for stuck jobs
stuckJobs, err := hm.findStuckJobs(ctx)
if err != nil {
log.Printf("Failed to check for stuck jobs: %v", err)
return
}
if len(stuckJobs) > 0 {
log.Printf("Found %d stuck jobs", len(stuckJobs))
}
}
func (hm *HealthMonitor) recoverStuckJobs(ctx context.Context) {
// Find jobs that have been "running" for too long
query := `
SELECT id, vendor_id, settlement_period, status, started_at, retry_count
FROM invoice_jobs
WHERE status = 'running'
AND started_at < NOW() - INTERVAL '30 minutes'
`
rows, err := hm.db.QueryContext(ctx, query)
if err != nil {
log.Printf("Failed to query stuck jobs: %v", err)
return
}
defer rows.Close()
for rows.Next() {
var job Job
err := rows.Scan(&job.ID, &job.VendorID, &job.SettlementPeriod,
&job.Status, &job.StartedAt, &job.RetryCount)
if err != nil {
log.Printf("Failed to scan stuck job: %v", err)
continue
}
log.Printf("Recovering stuck job %d", job.ID)
// Reset job status to pending for retry
_, err = hm.db.ExecContext(ctx,
"UPDATE invoice_jobs SET status = 'pending', started_at = NULL WHERE id = $1",
job.ID)
if err != nil {
log.Printf("Failed to reset stuck job %d: %v", job.ID, err)
continue
}
// Requeue the job
hm.workerPool.SubmitJob(&job)
}
}Code language: Go (go)7. Main Application with Graceful Shutdown
func main() {
// Initialize database connection
db, err := sql.Open("postgres", "postgres://user:pass@localhost/invoices?sslmode=disable")
if err != nil {
log.Fatal("Failed to connect to database:", err)
}
defer db.Close()
// Initialize Redis client
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
defer rdb.Close()
// Initialize services
pdfService := &PDFService{/* config */}
emailService := &EmailService{/* config */}
paymentService := &PaymentService{/* config */}
// Create processor
processor := &InvoiceProcessor{
db: db,
redis: rdb,
pdfService: pdfService,
emailService: emailService,
paymentService: paymentService,
}
// Wrap with retry logic
retryProcessor := &RetryableProcessor{
processor: processor,
maxRetries: 3,
retryDelay: 5 * time.Second,
}
// Create worker pool
workerPool := NewWorkerPool(retryProcessor, 10)
// Create health monitor
healthMonitor := &HealthMonitor{
db: db,
redis: rdb,
workerPool: workerPool,
checkInterval: 1 * time.Minute,
}
// Create context for graceful shutdown
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// Start components
workerPool.Start(ctx)
go healthMonitor.Start(ctx)
// Start job scheduler
go startJobScheduler(ctx, db, workerPool)
// Setup graceful shutdown
c := make(chan os.Signal, 1)
signal.Notify(c, os.Interrupt, syscall.SIGTERM)
log.Println("Invoice settlement system started")
// Wait for shutdown signal
<-c
log.Println("Shutting down gracefully...")
// Cancel context to stop all goroutines
cancel()
// Stop worker pool
workerPool.Stop()
log.Println("Shutdown complete")
}
// startJobScheduler creates jobs based on vendor settlement schedules
func startJobScheduler(ctx context.Context, db *sql.DB, workerPool *WorkerPool) {
ticker := time.NewTicker(1 * time.Hour) // Check every hour
defer ticker.Stop()
for {
select {
case <-ticker.C:
createScheduledJobs(ctx, db, workerPool)
case <-ctx.Done():
return
}
}
}
func createScheduledJobs(ctx context.Context, db *sql.DB, workerPool *WorkerPool) {
// Complex logic to determine which vendors need invoices
// Based on their settlement schedules and last invoice dates
query := `
SELECT vendor_id, settlement_period
FROM vendors v
WHERE NOT EXISTS (
SELECT 1 FROM invoice_jobs ij
WHERE ij.vendor_id = v.vendor_id
AND ij.status IN ('pending', 'running')
AND ij.created_at > NOW() - INTERVAL '1 day'
)
AND (
(settlement_period = 'daily' AND last_invoice_date < CURRENT_DATE)
OR (settlement_period = 'weekly' AND last_invoice_date < CURRENT_DATE - INTERVAL '7 days')
OR (settlement_period = 'monthly' AND last_invoice_date < CURRENT_DATE - INTERVAL '1 month')
)
`
rows, err := db.QueryContext(ctx, query)
if err != nil {
log.Printf("Failed to query vendors for scheduling: %v", err)
return
}
defer rows.Close()
for rows.Next() {
var vendorID int
var settlementPeriod string
if err := rows.Scan(&vendorID, &settlementPeriod); err != nil {
log.Printf("Failed to scan vendor: %v", err)
continue
}
// Create new job
job := &Job{
VendorID: vendorID,
SettlementPeriod: settlementPeriod,
Status: "pending",
CreatedAt: time.Now(),
}
// Insert job into database
err = db.QueryRowContext(ctx,
"INSERT INTO invoice_jobs (vendor_id, settlement_period, status, created_at) VALUES ($1, $2, $3, $4) RETURNING id",
job.VendorID, job.SettlementPeriod, job.Status, job.CreatedAt).Scan(&job.ID)
if err != nil {
log.Printf("Failed to create job for vendor %d: %v", vendorID, err)
continue
}
// Submit to worker pool
workerPool.SubmitJob(job)
log.Printf("Created and queued job %d for vendor %d", job.ID, vendorID)
}
}Code language: Go (go)The Complexity Challenge
Let’s visualize what we’ve built and the complexity involved:
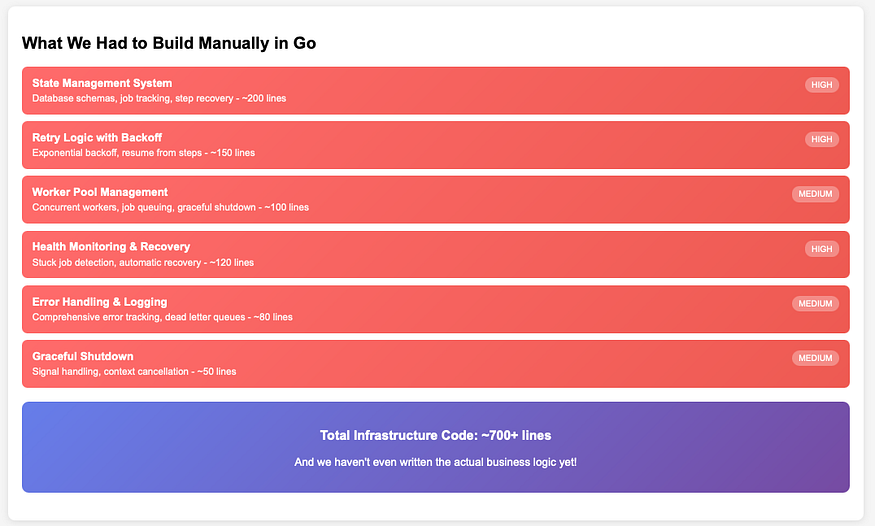
Pain Points We Discovered
1. Manual State Persistence
Every step needs explicit database tracking. If we forget to update the state, jobs can be lost or duplicated.
2. Complex Error Recovery
We had to anticipate every possible failure point and write custom recovery logic for each step.
3. Concurrency Complexity
Managing worker pools, preventing race conditions, and handling worker crashes requires significant effort.
4. Monitoring Overhead
Health checks, stuck job detection, and alerting systems all need custom implementation.
5. Testing Challenges
Testing failure scenarios is complex — we need to mock database failures, network timeouts, and partial state corruption.
The Infrastructure Tax
In Go, we spent 70% of our development time building infrastructure rather than business logic:
- Business Logic: Invoice generation, PDF creation, email sending (30%)
- Infrastructure: State management, retries, monitoring, error handling (70%)
This “infrastructure tax” is what makes building reliable systems in Go challenging. While Go gives you excellent performance and simplicity, it doesn’t give you fault tolerance for free.
What’s Next?
In Part 3, we’ll see how Elixir’s OTP (Open Telecom Platform) provides most of this infrastructure out of the box. Spoiler alert: the same system in Elixir will be about 80% less code with built-in fault tolerance.
The difference will be striking — where Go required us to manually build every reliability mechanism, Elixir’s OTP gives us:
- Automatic process supervision and restart
- Built-in state management
- Fault isolation between processes
- Hot code updates
- Distributed system primitives
This concludes Part 2 of our series. The full code examples above show the reality of building fault-tolerant systems in Go — it’s possible, but requires significant engineering effort to get right.
Below given the link for part-3