Think about your everyday online life. Have you ever been deep in an email conversation, where each message is a reply to a previous one, creating a long chain? Or maybe you’ve seen a lively discussion on X (the app formerly known as Twitter), where people reply to comments, and then others reply to those replies, building a huge, sprawling chat.
If you are not a medium subscriber, you can read full story here
These common online experiences show us a tricky but fascinating type of data: information that’s deeply connected, like branches on a tree. It’s not just emails and social media; imagine a company’s structure (who reports to whom), or products organized into main categories and then smaller sub-categories.
The big question for us, as programmers, is: how do we get this kind of linked data out of our databases in a smart and easy way? If we don’t know how many levels deep the connections go, a simple way of linking tables won’t work.
This is where a special trick in databases called Common Table Expressions (CTEs) comes in, especially the “recursive” kind. These are like magic tools that help us follow these deep connections. Even though CTEs are a database feature, Elixir, with its Ecto tool, now has a really clean way to use them right in your Elixir code. In this article, we’ll explain what these “recursive CTEs” are, why they’re perfect for finding these connected “threads” of information, and how to use Ecto’s with_cte/3 function to make it all happen smoothly.
CTEs are one of the database world’s best-kept secrets — super powerful but not always used. They offer a neat way to solve complex problems where data is linked in layers, problems that would otherwise make you jump through hoops with lots of database requests or complicated code. In this full guide, we’ll look closely at CTEs and then build a real Elixir app to show just how useful they are.
What is CTE?
A Common Table Expression is a named temporary result set that exists within the scope of a single SQL statement. Think of it as a virtual table that you can reference within your query, similar to a subquery but with enhanced readability and functionality.
CTEs come in two flavours:
Non-recursive CTEs act like named subqueries, helping organise complex queries into readable chunks.
Recursive CTEs are the real game-changers. They allow you to traverse hierarchical data structures in a single query, eliminating the need for multiple database calls or application-level recursion.
The Traditional Problem: Multiple Queries for Hierarchical Data
Consider a common scenario: you have a tagging system where tags can have parent tags, creating a hierarchy. Without CTEs, finding all ancestors of a tag requires multiple queries:
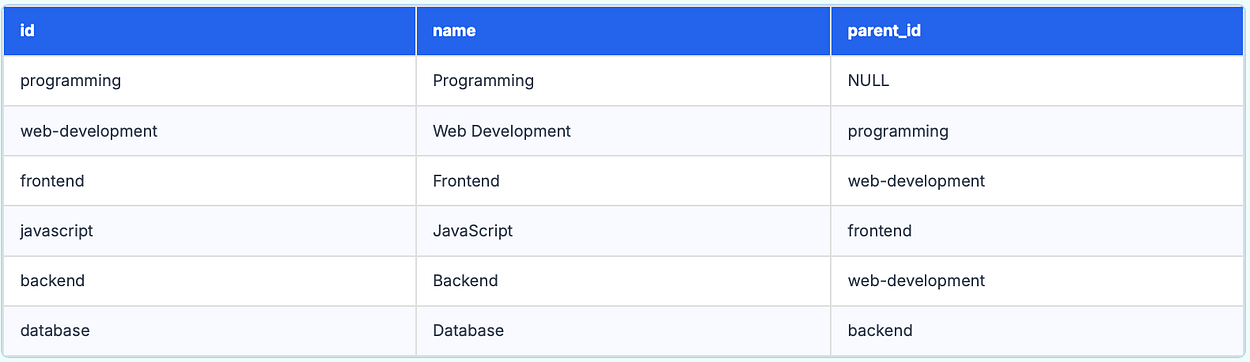
Suppose we have a table called tags which contains the tags list, which can be hierarchical i.e. one tag can be subtag/parent tag of the other tag, which represents the deeply nested structure within the table.
For simplicity let’s assume that there are 3 fields in the table and it looks like the following
-- Traditional approach: Multiple queries needed
-- Query 1: Find immediate parent
SELECT parent_id FROM tags WHERE id = 'web-development';
-- Result of
-- Query 2: Find parent's parent
SELECT parent_id FROM tags WHERE id = 'programming';Code language: SQL (Structured Query Language) (sql)This approach has several problems:
- Multiple database round trips increase latency
- Application logic becomes complex
- No guarantee of data consistency between queries
- Difficult to handle dynamic hierarchy depths
CTEs: The Elegant Solution
With recursive CTEs, we can traverse the entire hierarchy in a single query:
WITH RECURSIVE tag_hierarchy AS (
-- Base case: Start with the target tag
SELECT id, name, parent_id, 0 as level
FROM tags
WHERE id = 'web-development'
UNION ALL
-- Recursive case: Find parents
SELECT t.id, t.name, t.parent_id, th.level + 1
FROM tags t
INNER JOIN tag_hierarchy th ON t.id = th.parent_id
)
SELECT * FROM tag_hierarchy ORDER BY level;Code language: Elixir (elixir)This single query traverses the entire hierarchy, returning all ancestors with their levels. The recursive CTE works by:
- Base case: Starting with our target tag
- Recursive case: Joining with parent tags until no more parents exist
- Union: Combining all results into a single result set
To understand better we will visually see how the tag hierarchy is getting built up step by step
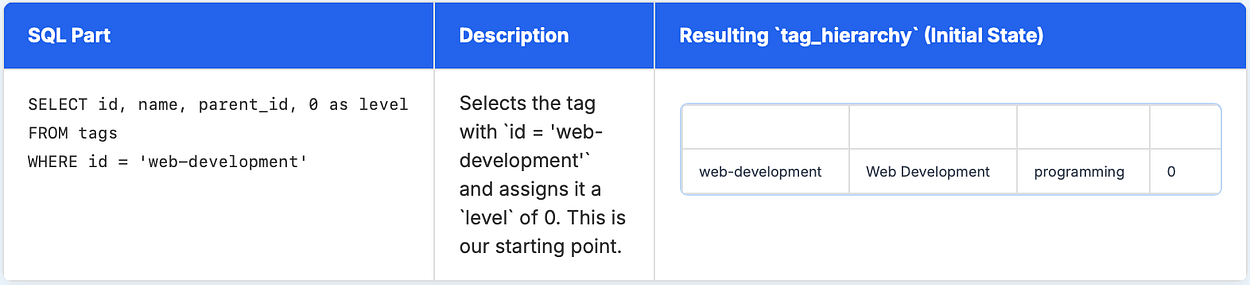
Step 1: The base case (Anchor member)
First case is the base case where we define our anchor member, this step is the non-recursive one and it defines the initial set of rows for the tag_hierarchy CTE.
Step 2: The Recursive Case — Iteration 1
The recursive part joins the tags table with the current context of the tag_hierarchy from step 1, it finds the tags whose id matches with the parent_id of rows already in the cte.

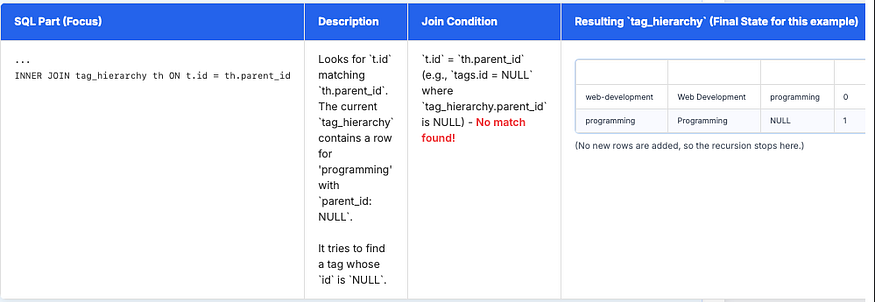
Step 3: The Recursive Case — Iteration 2 (and subsequent, if any)
The recursive part runs again, using the newly updated tag_hierarchy (now including programmingtag). It attempts to find parents of the newest rows.
Step 4: Final Selection
Once the recursive part has completed and no new rows can be added, the outer SELECT statement retrieves all data from the tag_hierarchy CTE and applies the final ORDER BY clause.

For the sake of simplicity I’ve explained upto 2 level but you can generalise it for nlevels 😃
Real-World Use Cases for CTEs
CTEs excel in scenarios involving hierarchical or graph-like data structures:
Organizational Charts: Finding all employees under a manager, calculating reporting chains, or determining organizational levels.
Category Trees: E-commerce sites with nested product categories, content management systems with hierarchical content organization.
Comment Systems: Threaded discussions where comments can reply to other comments, creating nested conversation trees.
File Systems: Directory structures, folder hierarchies, or any nested organizational system.
Network Analysis: Finding connected components, shortest paths, or analysing relationships in social networks.
Building a Practical Example with Elixir
First, let’s create a new Phoenix application
mix phx.new tag_hierarchy_demo --no-assets --no-html
cd tag_hierarchy_demoCode language: Elixir (elixir)Add the necessary dependencies to mix.exs
defp deps do
[
{:phoenix, "~> 1.7.0"},
{:ecto_sql, "~> 3.10"},
{:postgrex, "~> 0.17"},
{:jason, "~> 1.2"}
]
endCode language: Elixir (elixir)Creating the Database Schema
Let’s create a migration for our tags table
mix ecto.gen.migration create_tagsCode language: Elixir (elixir)Edit the migration file
defmodule TagHierarchyDemo.Repo.Migrations.CreateTags do
use Ecto.Migration
def change do
create table(:tags, primary_key: false) do
add :id, :string, primary_key: true
add :name, :string, null: false
add :description, :text
add :parent_id, references(:tags, type: :string, on_delete: :nilify_all)
add :level, :integer, default: 0
add :path, :string
timestamps()
end
create index(:tags, [:parent_id])
create unique_index(:tags, [:name])
create index(:tags, [:level])
end
endCode language: Elixir (elixir)Define the Tag schema
Make a new file lib/tag_hierarchy_demo/tags/tag.ex
defmodule TagHierarchyDemo.Tags.Tag do
use Ecto.Schema
import Ecto.Changeset
@primary_key {:id, :string, autogenerate: false}
@foreign_key_type :string
schema "tags" do
field :name, :string
field :description, :string
field :level, :integer, virtual: true
field :path, :string, virtual: true
belongs_to :parent, __MODULE__, type: :string
has_many :children, __MODULE__, foreign_key: :parent_id
timestamps()
end
def changeset(tag, attrs) do
tag
|> cast(attrs, [:id, :name, :description, :parent_id])
|> validate_required([:id, :name])
|> validate_length(:name, min: 2, max: 100)
|> validate_length(:description, max: 500)
|> unique_constraint(:name)
|> unique_constraint(:id)
|> validate_parent_not_self()
end
defp validate_parent_not_self(changeset) do
id = get_field(changeset, :id)
parent_id = get_field(changeset, :parent_id)
if id && parent_id && id == parent_id do
add_error(changeset, :parent_id, "cannot be the same as tag id")
else
changeset
end
end
endCode language: Elixir (elixir)Run the migration
mix ecto.migrateCode language: Elixir (elixir)Implementing CTE Queries with Ecto
Now we will build our context module TagHierarchyDemo.Tags
We will start from very scratch and go deep
Step 1: Basic Setup and Simple Queries
defmodule TagHierarchyDemo.Tags do
import Ecto.Query
alias TagHierarchyDemo.Repo
alias TagHierarchyDemo.Tags.Tag
# Basic operations - no CTEs yet
... You can implement these I'll just focus on the CTEs
# Get immediate children of a tag - simple query
def get_immediate_children(tag_id) do
from t in Tag,
where: t.parent_id == ^tag_id,
order_by: t.name
|> Repo.all()
end
# Get immediate parent of a tag - simple query
def get_immediate_parent(tag_id) do
from t in Tag,
join: p in Tag, on: t.parent_id == p.id,
where: t.id == ^tag_id,
select: p
|> Repo.one()
end
endCode language: Elixir (elixir)Above basic Ecto queries for parent-child relationships. This works fine for single-level operations but becomes inefficient for multi-level hierarchies.
Step 2: Understanding the Problem — Multiple Queries Approach
Let’s see why the traditional approach doesn’t scale
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# The old way - multiple database calls (inefficient!)
def get_ancestors_traditional(tag_id) do
get_ancestors_recursive(tag_id, [])
end
defp get_ancestors_recursive(nil, acc), do: Enum.reverse(acc)
defp get_ancestors_recursive(tag_id, acc) do
case get_tag(tag_id) do
nil -> Enum.reverse(acc)
tag ->
get_ancestors_recursive(tag.parent_id, [tag | acc])
end
end
endCode language: Elixir (elixir)Problems with this approach:
- Multiple database round trips (N+1 problem)
- Inconsistent data if hierarchy changes between calls
- Complex application logic
- Poor performance with deep hierarchies
Step 3: Your First CTE — Simple Non-Recursive
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# Simple CTE example - tags with their immediate children count
def get_tags_with_child_count do
child_count_cte =
from t in Tag,
group_by: t.parent_id,
select: %{parent_id: t.parent_id, child_count: count(t.id)}
from t in Tag,
left_join: cc in subquery(child_count_cte), on: t.id == cc.parent_id,
select: map(t, [:id, :name, :description]),
select_merge: %{immediate_children_count: coalesce(cc.child_count, 0)},
order_by: t.name
|> Repo.all()
end
endCode language: PHP (php)CTEs help organize complex queries by breaking them into named, reusable parts. This is still not recursive, but shows the CTE concept.
Step 4: Your First Recursive CTE — Finding Ancestors
Now let’s implement our first recursive CTE
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# Simple recursive CTE - find all ancestors
def get_ancestors_simple(tag_id) do
# Step 1: Define the base case (starting point)
initial_query =
from t in Tag,
where: t.id == ^tag_id,
select: map(t, [:id, :name, :description, :parent_id]),
select_merge: %{level: 0} # To Track how many levels up
# Step 2: Build the recursive CTE
Tag
|> recursive_ctes(true) # Enable recursive CTEs
|> with_cte("ancestors", as: ^initial_query) # Name our CTE "ancestors"
|> join(:inner, [t], a in "ancestors", on: t.id == a.parent_id) # Find parents
|> select([t, a], map(t, [:id, :name, :description, :parent_id]))
|> select_merge([t, a], %{level: a.level + 1}) # Increment level
|> union_all(^initial_query) # Combine base case with recursive case
|> order_by([t], t.level)
|> Repo.all()
end
endCode language: Elixir (elixir)Breaking down the recursive CTE:
- Base case: Start with the target tag at level 0
- Recursive case: Find parent of current tag, increment level
- Union: Combine base case with recursive results
- Termination: Automatically stops when no more parents found
Step 5: Adding Safety — Preventing Infinite Loops
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# Safe recursive CTE with loop prevention
def get_ancestors_safe(tag_id) do
initial_query =
from t in Tag,
where: t.id == ^tag_id,
select: map(t, [:id, :name, :description, :parent_id]),
select_merge: %{
level: 0,
path: fragment("ARRAY[?]", t.id) # Track visited nodes
}
Tag
|> recursive_ctes(true)
|> with_cte("ancestors", as: ^initial_query)
|> join(:inner, [t], a in "ancestors", on: t.id == a.parent_id)
|> where([t, a], fragment("NOT ? = ANY(?)", t.id, a.path)) # Avoid cycles
|> select([t, a], map(t, [:id, :name, :description, :parent_id]))
|> select_merge([t, a], %{
level: a.level + 1,
path: fragment("? || ?", a.path, t.id) # Add to path
})
|> union_all(^initial_query)
|> order_by([t], t.level)
|> Repo.all()
end
endCode language: Elixir (elixir)New safety features:
- Path tracking: Store array of visited node IDs
- Cycle detection: Skip nodes already in path
- Automatic termination: Prevents infinite loops
Step 6: Reversing the Direction — Finding Descendants
Now let’s find all descendants (children, grandchildren, etc.):
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# Find all descendants of a tag
def get_descendants_simple(tag_id) do
initial_query =
from t in Tag,
where: t.id == ^tag_id,
select: map(t, [:id, :name, :description, :parent_id]),
select_merge: %{level: 0}
Tag
|> recursive_ctes(true)
|> with_cte("descendants", as: ^initial_query)
|> join(:inner, [t], d in "descendants", on: t.parent_id == d.id) # Find children
|> select([t, d], map(t, [:id, :name, :description, :parent_id]))
|> select_merge([t, d], %{level: d.level + 1})
|> union_all(^initial_query)
|> with_cte("descendants", as: ^(&1)) # Reference the complete CTE
|> from(d in "descendants", where: d.level > 0) # Exclude the starting tag
|> order_by([d], [d.level, d.name])
|> Repo.all()
end
endCode language: Elixir (elixir)Key differences from ancestors:
- Join direction:
t.parent_id == d.id(children point to parents) - Filtering: Exclude starting tag with
level > 0 - Same safety: Can add path tracking here too
Step 7: Building the Complete Tree
Let’s create a function that shows the entire hierarchy
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# Get complete hierarchy starting from roots
def get_full_hierarchy do
# Start with root tags (no parent)
roots_query =
from t in Tag,
where: is_nil(t.parent_id),
select: map(t, [:id, :name, :description, :parent_id]),
select_merge: %{
level: 0,
path: t.name # Build readable path
}
Tag
|> recursive_ctes(true)
|> with_cte("hierarchy", as: ^roots_query)
|> join(:inner, [t], h in "hierarchy", on: t.parent_id == h.id)
|> select([t, h], map(t, [:id, :name, :description, :parent_id]))
|> select_merge([t, h], %{
level: h.level + 1,
path: fragment("? || ' > ' || ?", h.path, t.name) # Build breadcrumb path
})
|> union_all(^roots_query)
|> with_cte("hierarchy", as: ^(&1))
|> from(h in "hierarchy")
|> order_by([h], h.path) # Order by full path for tree-like display
|> Repo.all()
end
endCode language: Elixir (elixir)What this gives us:
- Complete tree structure in one query
- Readable paths like “Technology > Programming > Web Development”
- Proper ordering for display
Let’s implement a more complex pattern — finding common ancestors
Advanced Patterns
Common Ancestors
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# Find common ancestor of two tags (simplified approach)
def find_common_ancestor(tag_id1, tag_id2) do
# Get ancestors of both tags
ancestors1 = get_ancestors_safe(tag_id1) |> Enum.map(& &1.id)
ancestors2 = get_ancestors_safe(tag_id2) |> Enum.map(& &1.id)
# Find intersection
common_ids = MapSet.intersection(MapSet.new(ancestors1), MapSet.new(ancestors2))
# Get the closest common ancestor (lowest level)
case MapSet.to_list(common_ids) do
[] -> nil
[common_id] -> get_tag(common_id)
multiple_ids ->
# Return the one with highest level (closest to our tags)
get_ancestors_safe(tag_id1)
|> Enum.find(fn ancestor -> ancestor.id in multiple_ids end)
end
end
endCode language: Elixir (elixir)Utility Functions
defmodule TagHierarchyDemo.Tags do
# ... previous code ...
# Get siblings of a tag
def get_siblings(tag_id) do
case get_tag(tag_id) do
nil -> []
tag ->
from t in Tag,
where: t.parent_id == ^tag.parent_id and t.id != ^tag_id,
order_by: t.name
|> Repo.all()
end
end
# Check if one tag is ancestor of another
def is_ancestor?(potential_ancestor_id, tag_id) do
get_ancestors_safe(tag_id)
|> Enum.any?(fn ancestor -> ancestor.id == potential_ancestor_id end)
end
# Get all tags at a specific level in the hierarchy
def get_tags_at_level(target_level) do
roots_query =
from t in Tag,
where: is_nil(t.parent_id),
select: map(t, [:id, :name, :description, :parent_id]),
select_merge: %{level: 0}
Tag
|> recursive_ctes(true)
|> with_cte("levels", as: ^roots_query)
|> join(:inner, [t], l in "levels", on: t.parent_id == l.id)
|> select([t, l], map(t, [:id, :name, :description, :parent_id]))
|> select_merge([t, l], %{level: l.level + 1})
|> union_all(^roots_query)
|> with_cte("levels", as: ^(&1))
|> from(l in "levels", where: l.level == ^target_level)
|> order_by([l], l.name)
|> Repo.all()
end
endCode language: Elixir (elixir)Testing
# Test basic operations
{:ok, tech} = Tags.create_tag(%{id: "tech", name: "Technology"})
{:ok, prog} = Tags.create_tag(%{id: "prog", name: "Programming", parent_id: "tech"})
{:ok, web} = Tags.create_tag(%{id: "web", name: "Web Development", parent_id: "prog"})
# Test immediate relationships
Tags.get_immediate_children("tech") # Should return [Programming]
Tags.get_immediate_parent("prog") # Should return Technology
# Test CTE functions
Tags.get_ancestors_simple("web") # Should return [Web Dev, Programming, Technology]
Tags.get_descendants_simple("tech") # Should return [Programming, Web Development]
Tags.get_full_hierarchy() # Should show complete treeCode language: Elixir (elixir)Key Learning Points
By breaking down the implementation step by step, readers can:
- Understand the progression: From simple queries to complex CTEs
- See the problems solved: Why CTEs are better than multiple queries
- Learn safety patterns: How to prevent infinite loops
- Grasp the concepts: Each function builds on previous knowledge
- Test incrementally: Verify understanding at each step
Performance Considerations with Ecto CTEs
When using Ecto CTEs, keep these performance tips in mind:
Use limits and guards: Prevent runaway recursion with depth limits.
Index parent_id columns: Ensure your hierarchical foreign keys are indexed.
Consider materialized paths: For frequently queried hierarchies, store pre-computed paths.
Monitor query plans: Use EXPLAIN ANALYZE to understand how PostgreSQL executes your CTEs.
Conclusion
Using Ecto’s native CTE support provides the best of both worlds: the power of recursive CTEs with the safety and maintainability of Elixir’s type system and query builder. Instead of writing raw SQL fragments, you can leverage Ecto’s composable query syntax while still accessing advanced database features.
This approach offers several advantages over raw SQL:
- Type safety: Ecto validates your queries at compile time
- Composability: You can build complex queries by combining smaller parts
- Maintainability: Elixir syntax is more readable and maintainable than SQL strings
- Database agnostic: Your queries work across different database adapters
- Integration: Seamless integration with your schemas and changesets
The combination of Ecto’s query DSL with PostgreSQL’s recursive CTEs provides a powerful foundation for handling complex hierarchical data in your Elixir applications. Whether you’re building content management systems, organizational charts, or any application with tree-like data structures, this approach will serve you well.
I hope you have enjoyed this long article. if you liked it 🙂 consider buying a coffee ☕️ here